Objetivo y problema
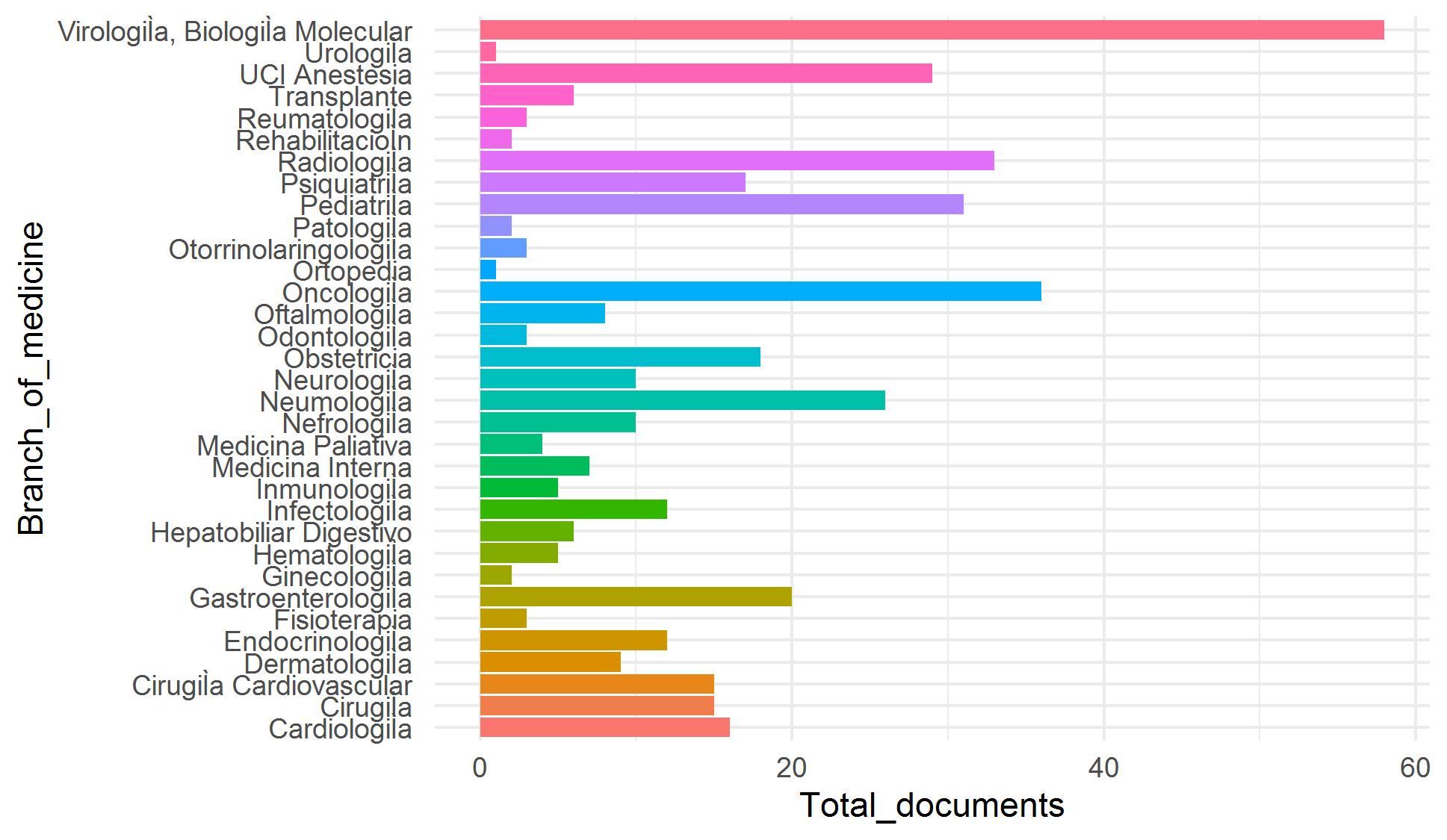
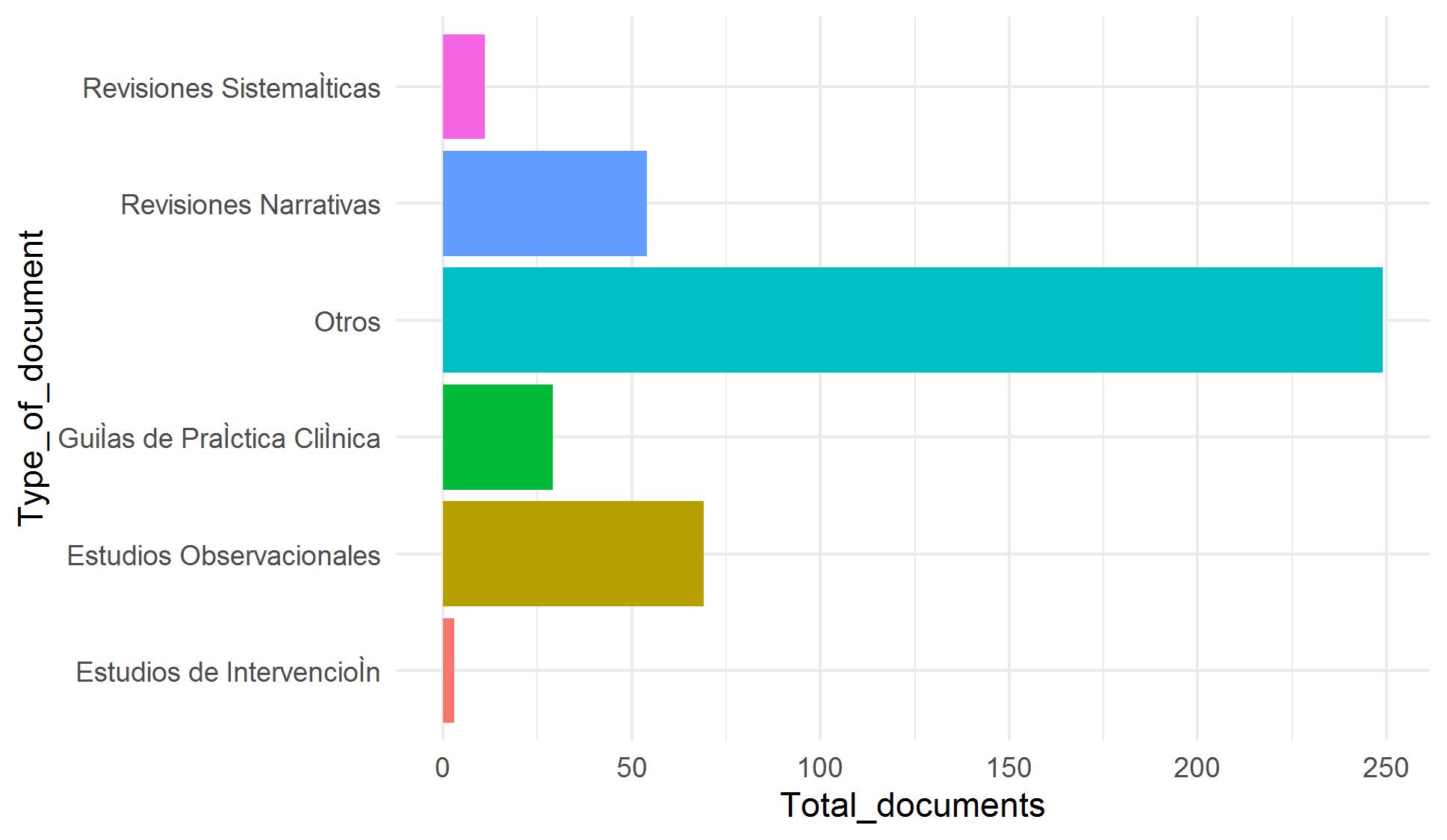
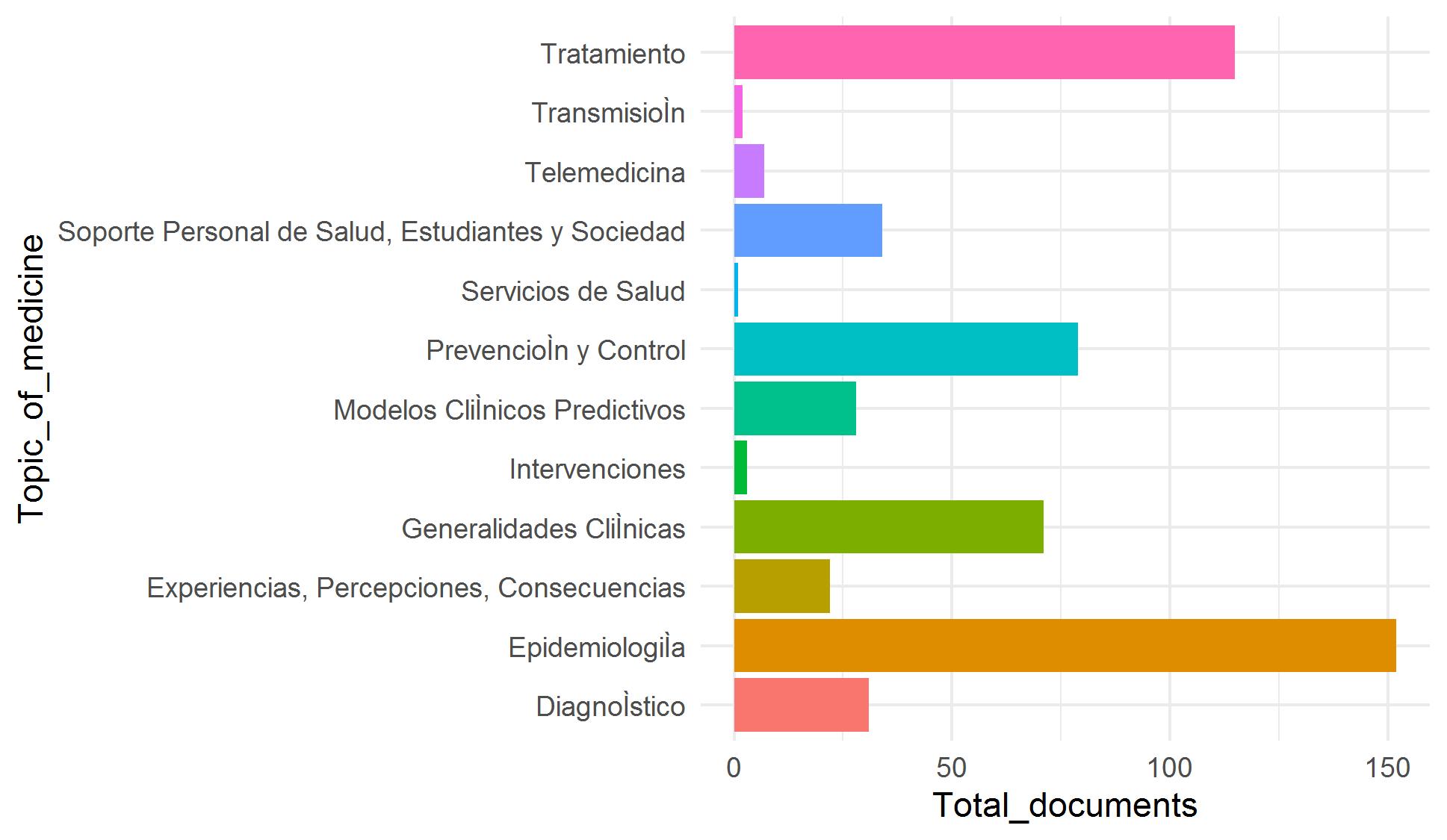
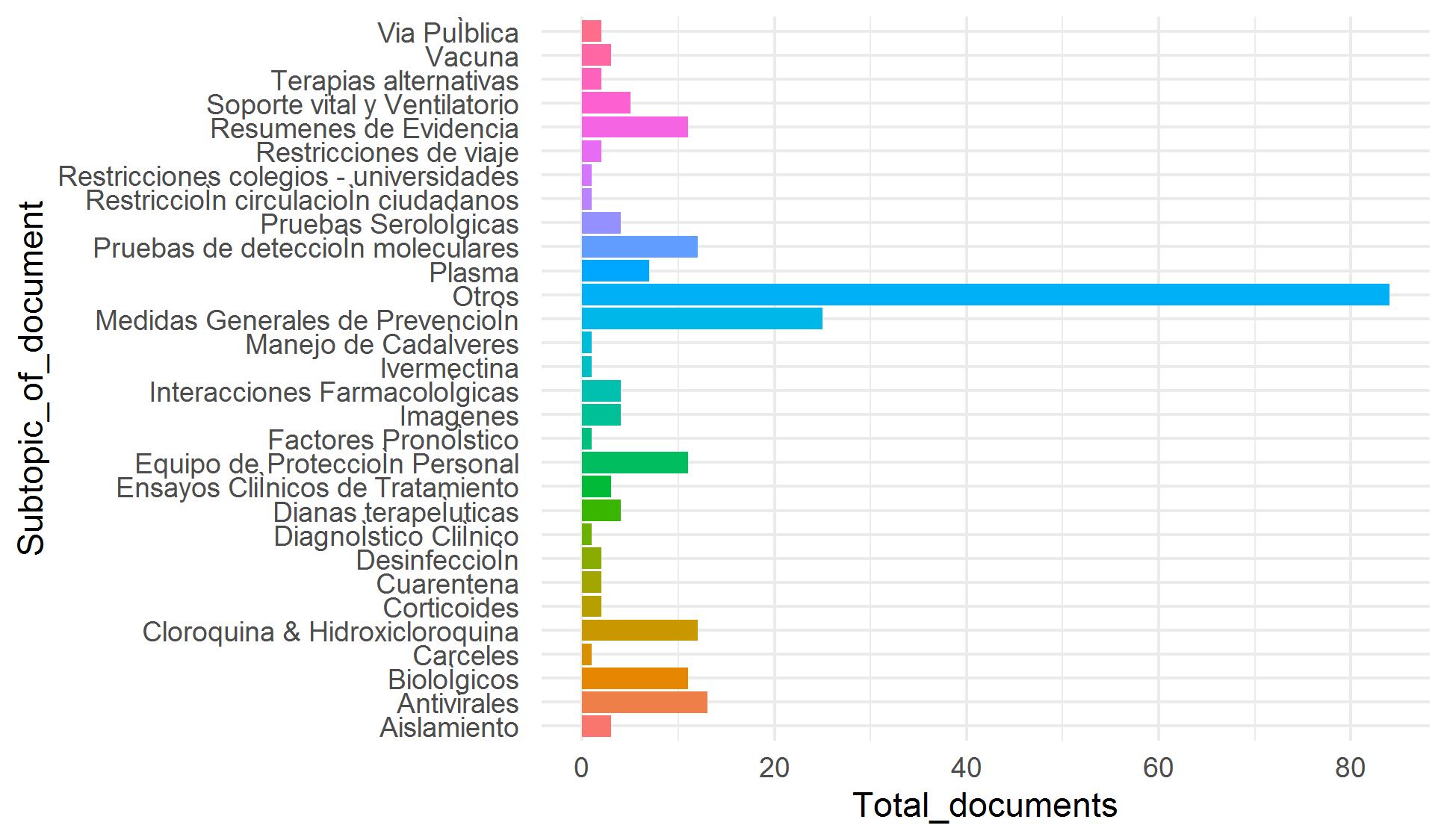
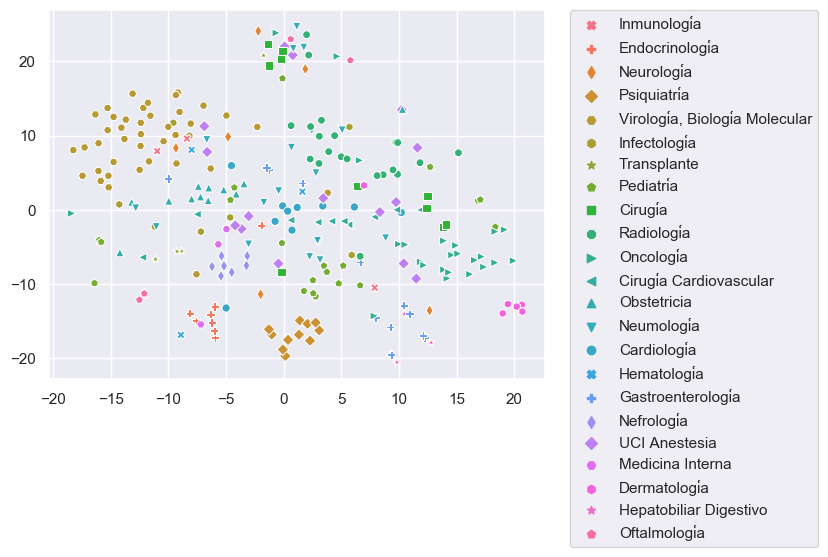
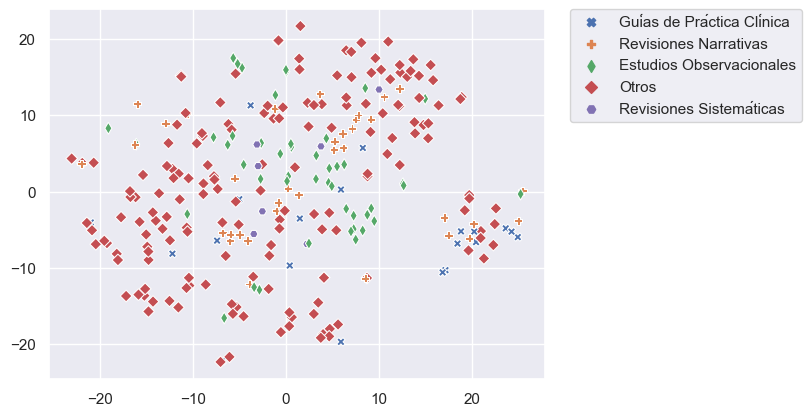
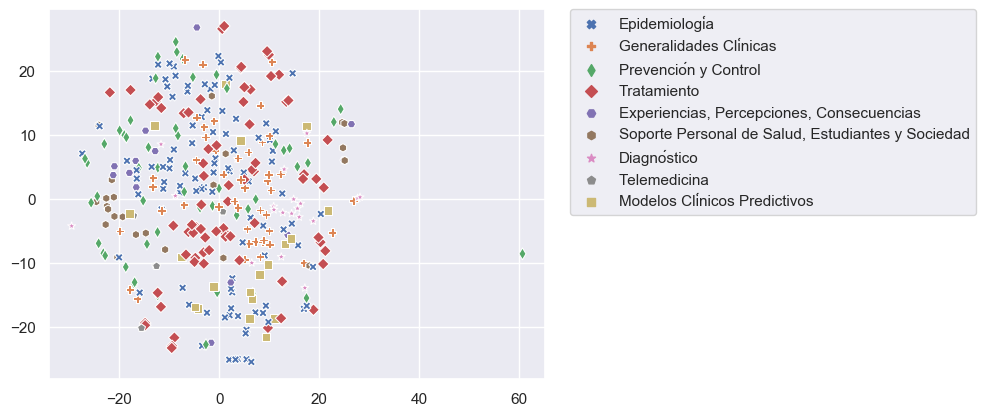
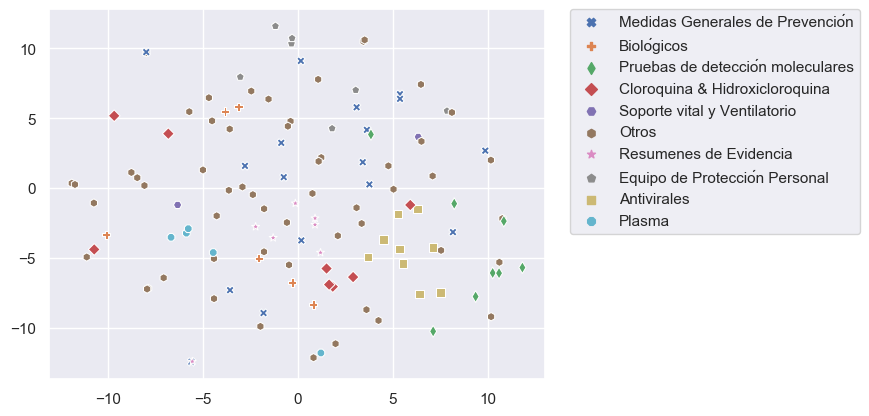
Nuestro objetivo es incorporar miles de artículos de las colecciones de Elsevier y LitCovid a nuestro repositorio COVID-19. Debido a que la clasificación manual de estos artículos es demandante y requiere mucho tiempo, hemos trabajado en una estrategia de clasificación asistida utilizando técnicas de aprendizaje supervisado y utilizando artículos clasificados manualmente como datos de entrenamiento. Nos enfrentamos a cuatro problemas para lograr este objetivo: pocos datos de entrenamiento y clases desequilibradas (categorías con pocos ejemplos) (Figura 1), categorías con datos traslapados (especialmente para Tema) (Figura 2) y alta dimensionalidad (pocas filas y muchas columnas).
 |
 |
|
 |
 |
|
 |
 |
|
 |
 |
|
Clasificación asistida
Para abordar el desafío de clasificar los miles de documentos de las colecciones de Elsevier y LitCovid, propusimos una estrategia de curación asistida utilizando el valor de la probabilidad de decisión asignada por el clasificador para cada documento. Para todos los artículos clasificados automáticamente, mostraremos el valor de probabilidad a médicos participantes del proyecto. Entonces, ellos pueden ahorrar tiempo y esfuerzo iniciando el proceso de revisión manual utilizando los valores más altos. Después de revisar y clasificar manualmente un grupo de documentos, podremos establecer un umbral del valor de probabilidad. Todos los documentos con valor de probabilidad mayor este umbral se podrán publicar automáticamente en nuestro repositorio COVID-19. Además, el conjunto de documentos clasificados manualmente se utilizará para aumentar los datos de entrenamiento para una mejor clasificación automática.
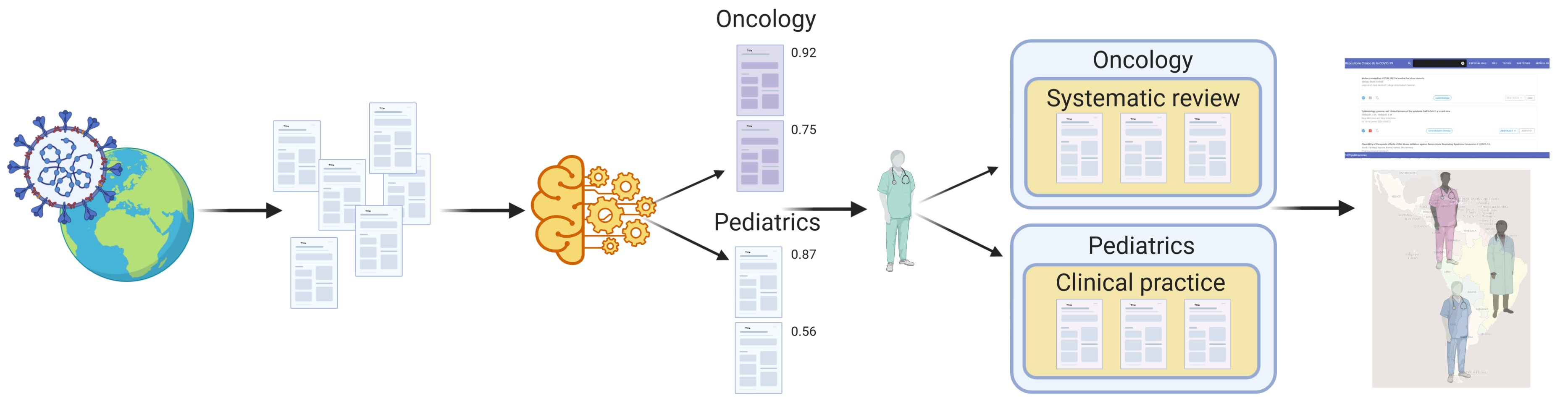 |
Metodología
Resolvimos los problemas probando diferentes técnicas (Figura 3). Para la reducción de dimensionalidad , probamos x2 (CHI2) y truncamiento por descomposición de valor singular (truncated-SVD). Las dimensiones finales probadas fueron 50, 100, 150, 200, 250, y 300. Para aumentar los datos de entrenamiento , seleccionamos documentos muy similares de la colección de Elsevier, usando similitud coseno, a un vector de categoría formado por todas las palabras de los documentos de la categoría. La última técnica que probamos fue la creación de características utilizando palabras clave seleccionadas manualmente de las palabras más frecuentes de todos los documentos de una categoría.
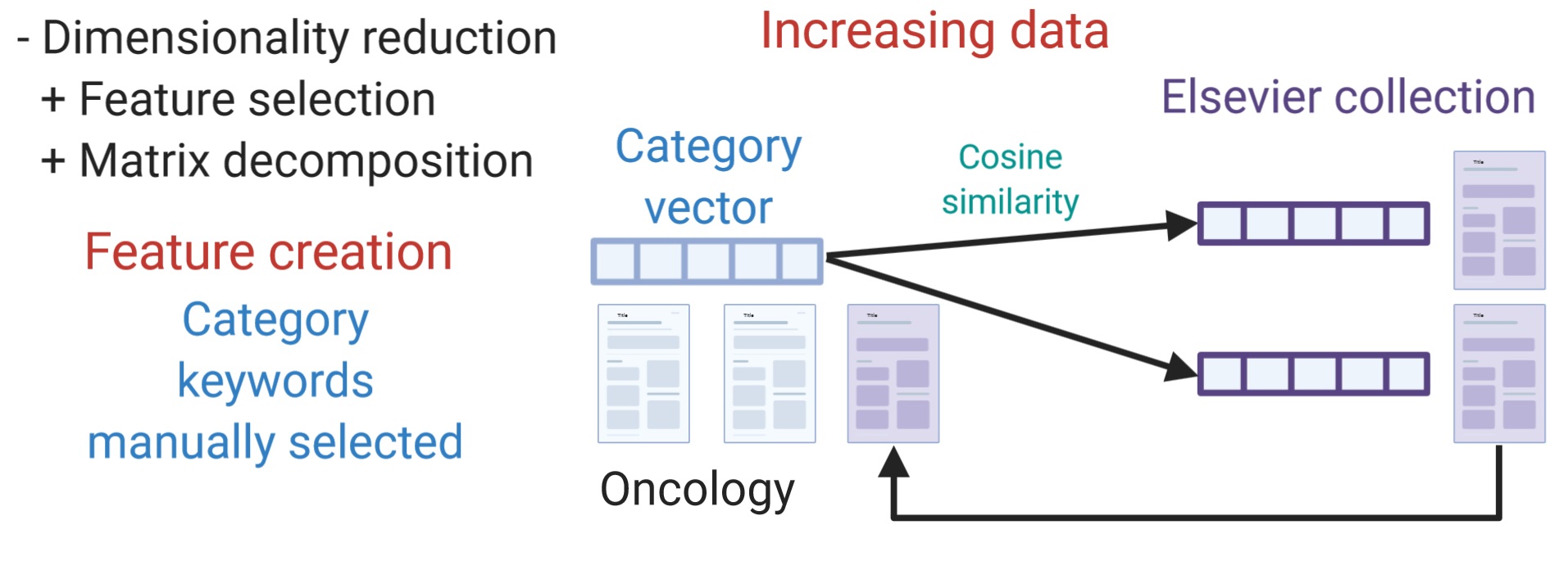 |
Probamos diferentes algoritmos de aprendizaje para clasificación automática: Bernoulli Naïve Bayes (BernoulliNB), Multinomial Naïve Bayes (MultinomialNB), Complement Naïve Bayes (ComplementNB), Support Vector Machines (SVM) con Radial-basis function kernel (rbf) y linear kernel, k-nearest neighbors (kNN), Random Forest, y Stochastic Gradient Descent (SGDClassifier). Además, probamos vectorizaciones de los documentos binarias y de frecuencia, así como de peso TF-IDF. Realizamos afinación de hiperparámetros.
Resultados
Por un lado, la clasificación automática funcionó mejor para las clases de especialidad (branch) y tipo (type) (Tabla 1), ambas usando lemas obtenidos del título, medio, palabras clave y resumen. Nuestra estrategia para aumentar los datos utilizando documentos muy similares (Increase) mejoró las puntuaciones. Por otro lado, hay que mejorar nuestros resultados para las clases por tema (topic) y subtema (subtopic), donde la mejor estrategia fue no aumentar los datos de entrenamiento usando lemas de solo el título, medio y palabras clave. La reducción de dimensionalidad aumentó la puntuación de los clasificadores, tres de ellos con truncamiento con SVD y uno con x2. Una observación final es que, si bien diferentes algoritmos de aprendizaje lograron mejores resultados para diferentes clases, todos los clasificadores se desempeñaron mejor con la vectorización TF-IDF.
Tabla 1. Valores de evaluación para los mejores clasificadores y sus características
| Categoría | Técnica | Clasificador | Características | Precision | Recall | F-score |
|---|---|---|---|---|---|---|
| Especialidad | Incrementar datos / Creación de características | SGDClassifier, TF-IDF, SVD-200 | Título, medio, palabras clave y abstract | 0.77 | 0.68 | 0.70 |
| Tipo | Incrementar datos / Creación de características | SVM-rbf, TF-IDF, SVD-50 | Título, medio, palabras clave y abstract | 0.81 | 0.80 | 0.80 |
| Tema | No incrementar datos / Creación de características | SVM-rbf, TF-IDF, SVD-150 | Título, medio y palabras clave | 0.64 | 0.61 | 0.61 |
| Subtema | No incrementar datos / Creación de características | BernoulliNB, TF-IDF, CHI2-250 | Título, medio y palabras clave | 0.73 | 0.65 | 0.65 |