What is L-Covid?
It is a web environment that integrates several NLP-powered components to facilitate the reading process, the identification of connected ideas and, in general, the exploration of COVID-19 literature.
Why we did it?
Because of the deluge of published scientific knowledge and the challenge to keep up to date that we had been experimenting in the last years has but exacerbated with the urgency of COVID-19 pandemic. This has resulted in that involved actors faced a lack of easy means to explore and make sense of the vast amount of new publications. Moreover, considering that different actors search for specific information relevant to their respective duties, frequently, the needed knowledge is found fragmented across various publications. Another important point is that with so many parallel researches, the ability to quickly retrieve and contrast similar statements (that could support or refute) is critical.
How we tackle it
A EXPLORATION ENVIRONMENT. We propose a smart literature analysis environment, which includes several NLP-powered components to enable a more efficient reading process. The following two strategies are the core of our environment.
TRANSVERSAL READING. We propose a semantically-guided transversal reading. We believe that this type of reading can significantly benefit the process of grasping the prominent opinion and state-of-the-art of a particular aspect. Our strategy to provide this feature was to interlink all semantically related sentences by semantic-textual-similarity (STS).
SEMANTIC ENRICHMENT. We enrich the literature with named-entity recognition and disambiguation (NERD), using the major life science databases as entity sources, enable named-entity searches, provide network-graphs of the most interconnected publications and, an interactive tool to highlight the most central statements within an article.
Methodology
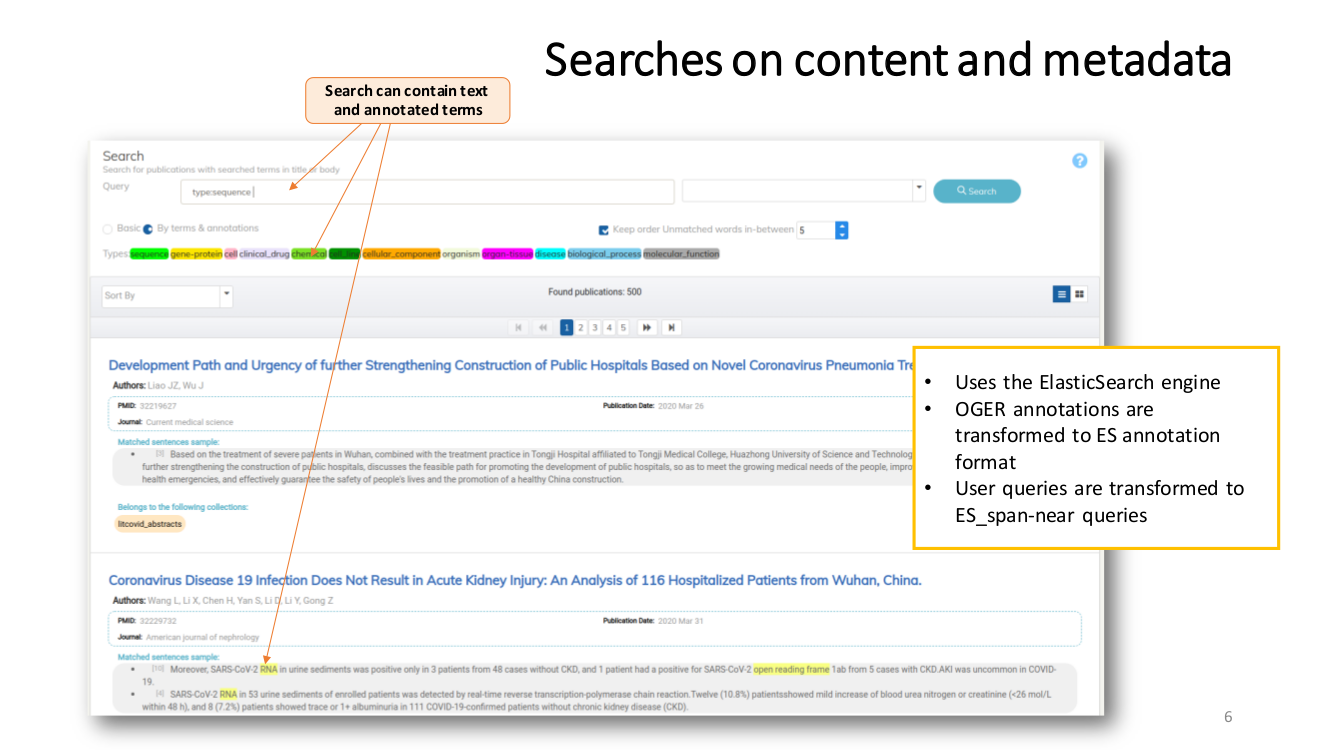
Named Entity Recognition and Disambiguation (NERD). These capabilities are provided by OGER, a state-of-the-art biomedical NER annotator which in turn depends on the Bio Term Hub (BTH). BTH is a combined terminological resource created by dynamically sourcing entity names and their identifiers from reference databases. The OntoGene’s Biomedical Entity Recogniser (OGER) is a RESTful web service implemented on top of the BTH which allows a remote user to batch annotate a collection of documents.
Semantic Textual Similarity (STS). Our approach to measure STS is representing the sentences as embeddings and then use the cosine between two embeddings as their semantic similarity. To compute the embeddings we used SciBERT, an unsupervised transformer language model pre-trained in the scientific literature. First, we map tokens to embeddings and then apply mean pooling to get fixed-sized sentence vectors. Due to the lack of STS corpora specific to the COVID-19 literature we did not apply any fine-tuning.

Results




Related publications
- Lithgow-Serrano O, Lopez-Fuentes A, Balderas-Martínez Y, Rinaldi F, Collado-Vides J. A smart literature exploration environment for COVID-19 literature. Poster presentede at: NLP COVID-19 Workshop at ACL 2020, 09-10 July, Seattle, Washington, USA. https://www.nlpcovid19workshop.org/posters/ [Poster]
- Lithgow-Serrano O, Lopez-Fuentes A, Balderas-Martínez Y, Rinaldi F, Collado-Vides J. Semantically-enriched environment for COVID-19 literature exploration. Poster presented at: COVID-19, 28th Conference on Intelligent Systems for Molecular Biology (ISMB 2020), 13-16 July, Montreal, Quebec, Canada.
- Lithgow-Serrano O, Lopez-Fuentes A, Balderas-Martínez Y, Rinaldi F, Collado-Vides J. (2020) A smart literature exploration environment for COVID-19 literature. Manuscript in preparation. In OpenReview.net