Goal and problem
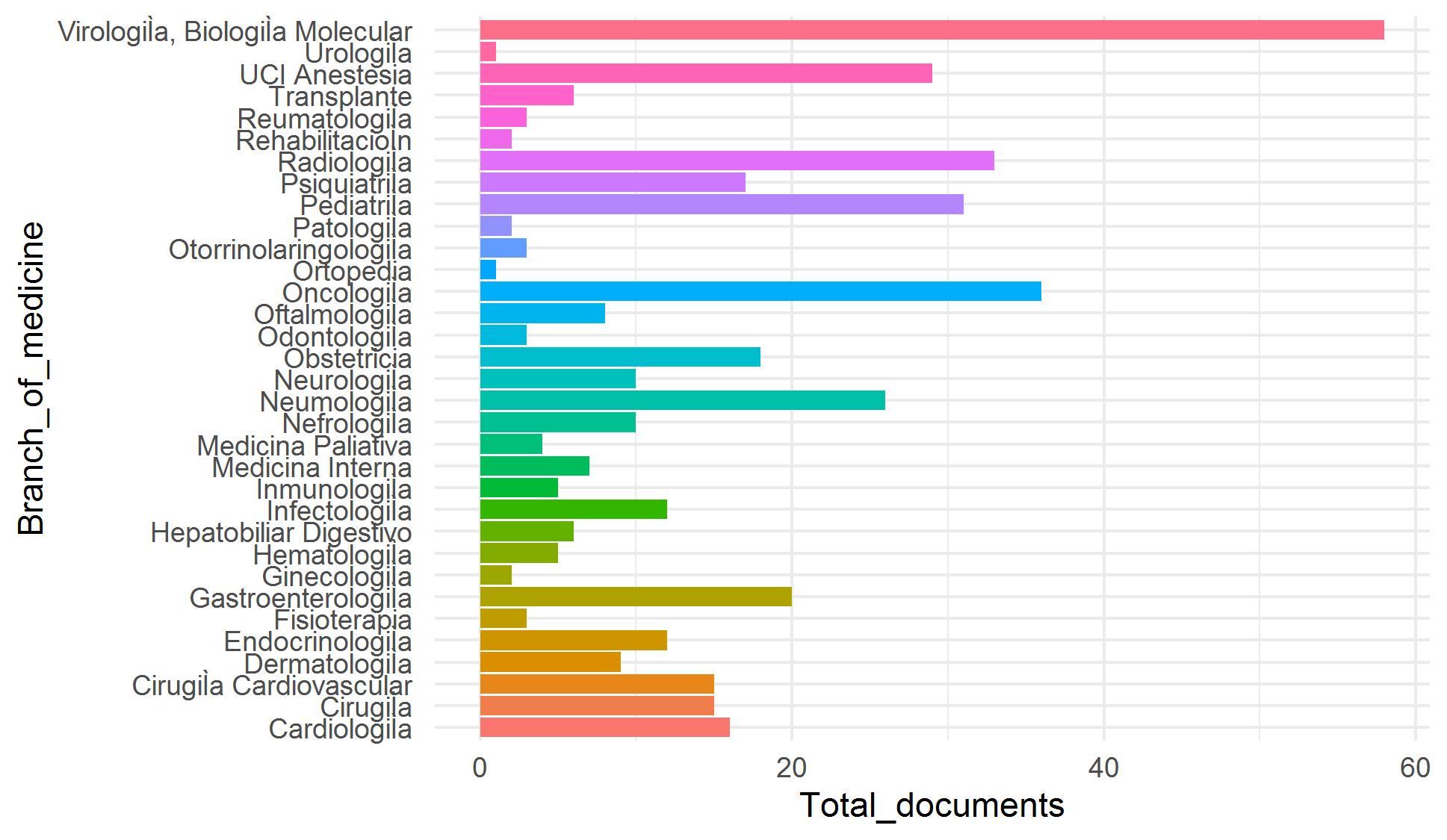
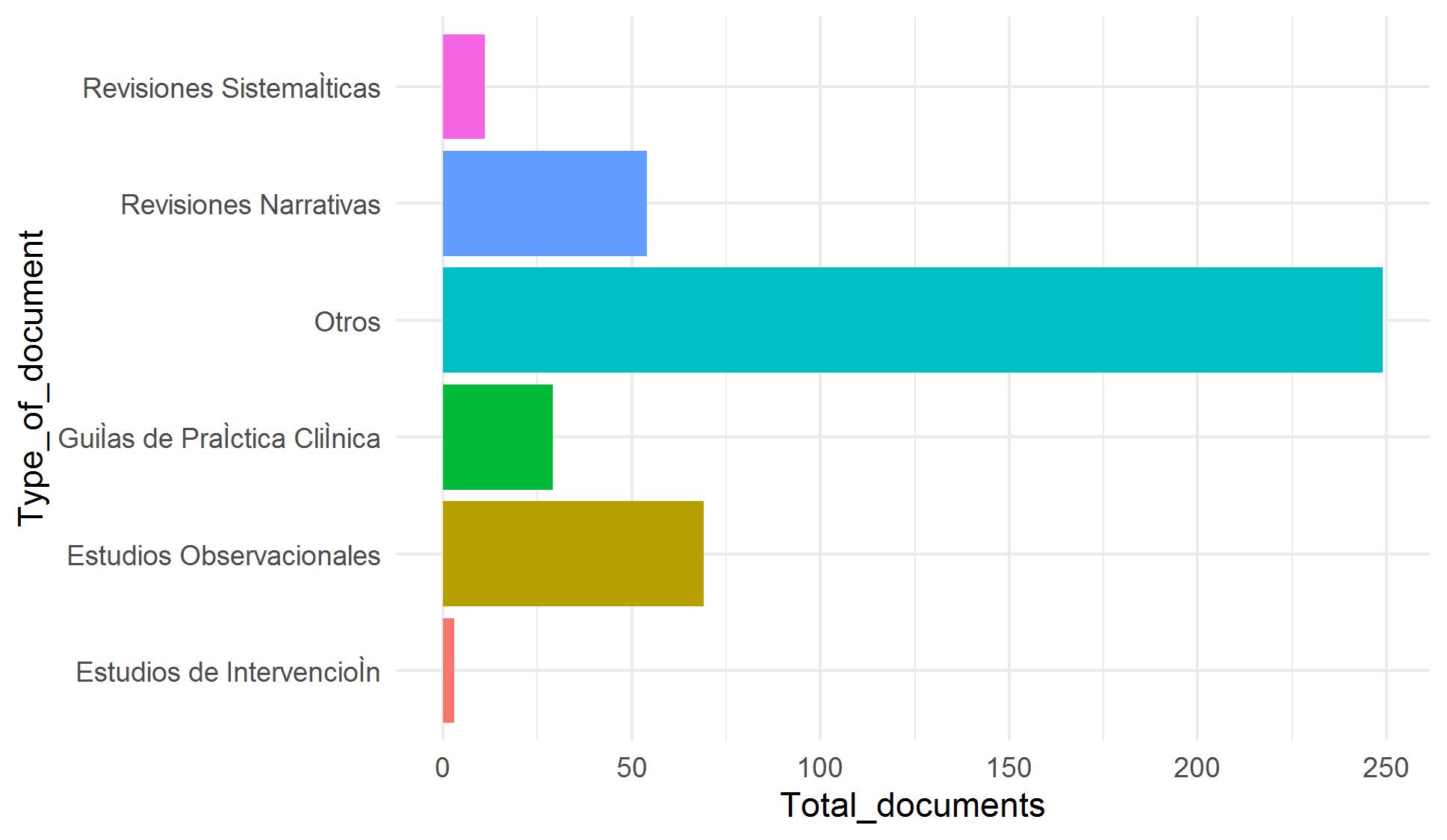
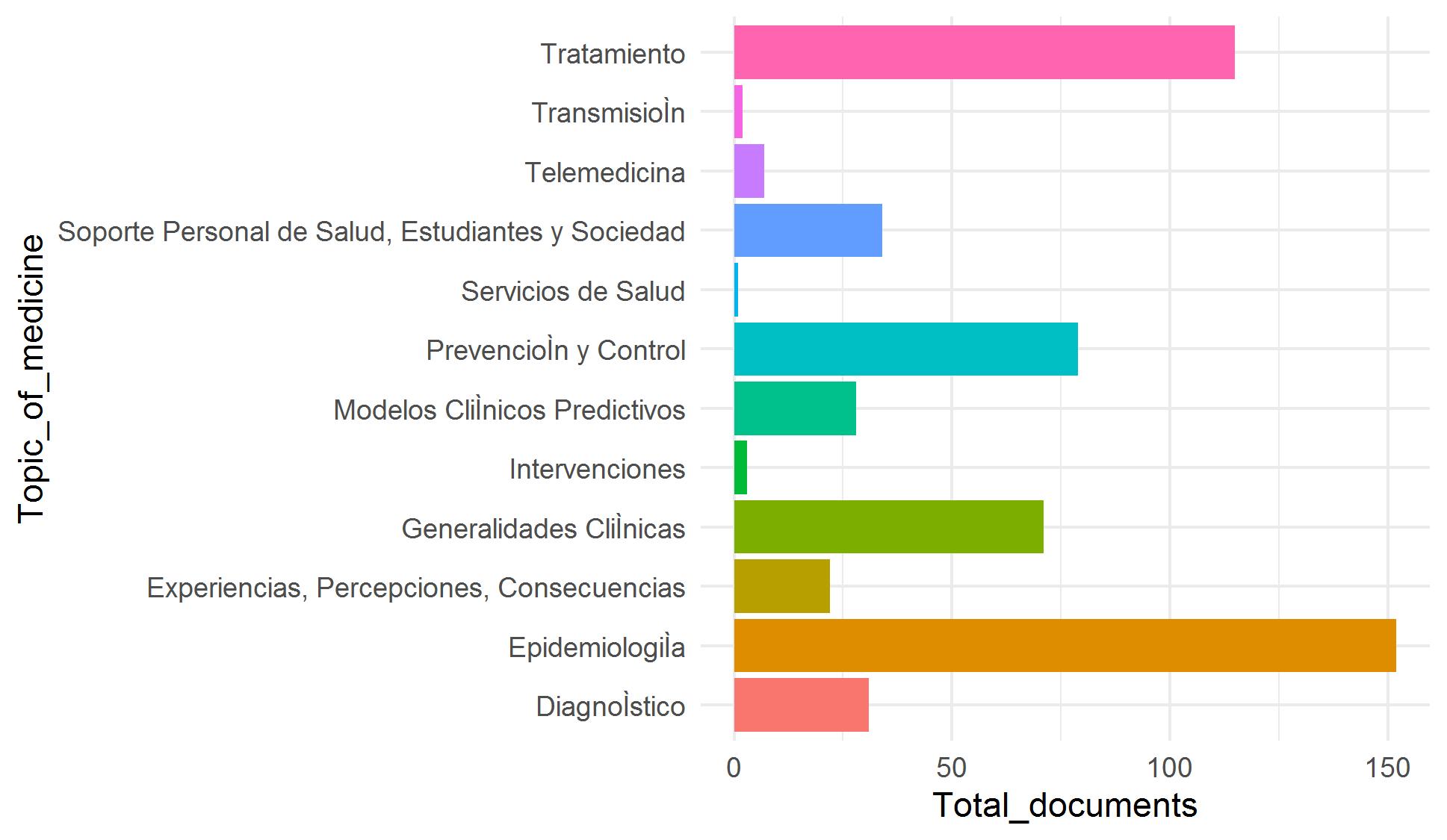
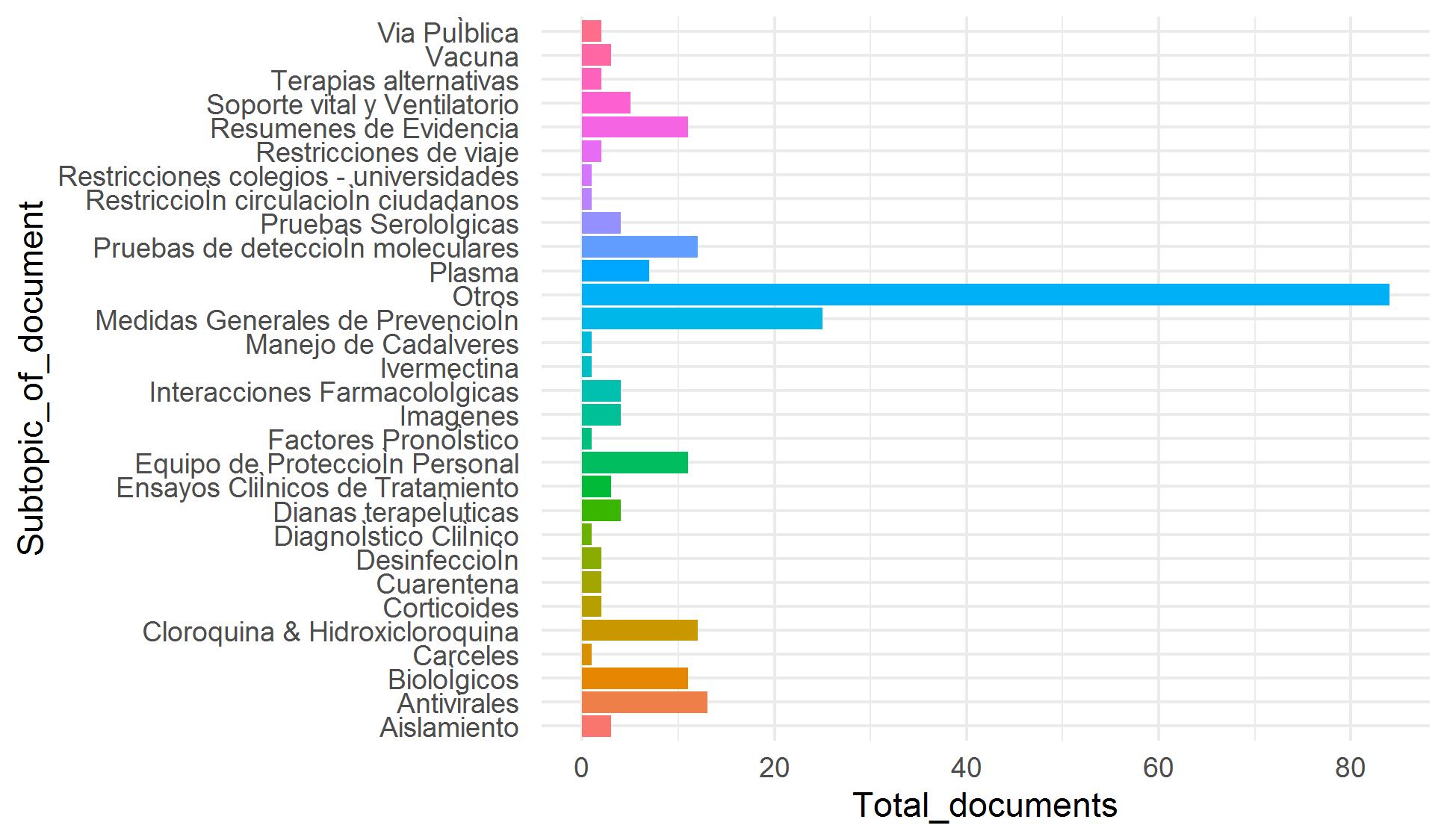
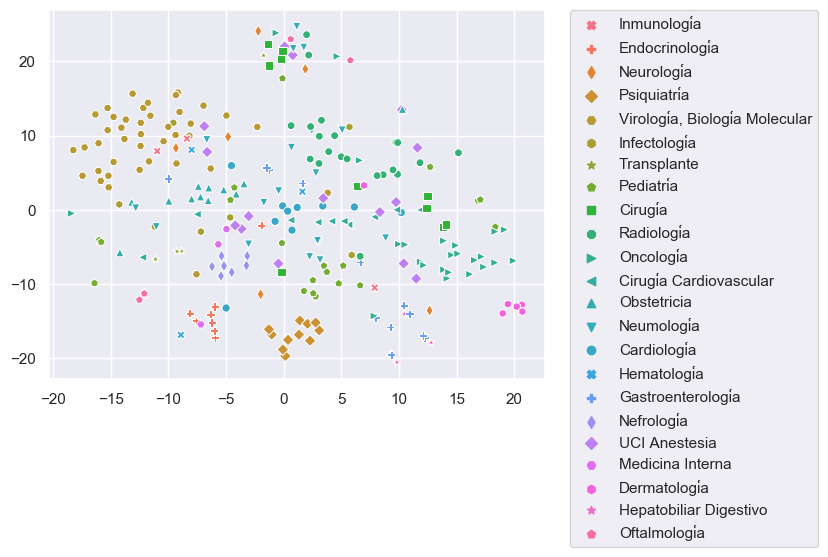
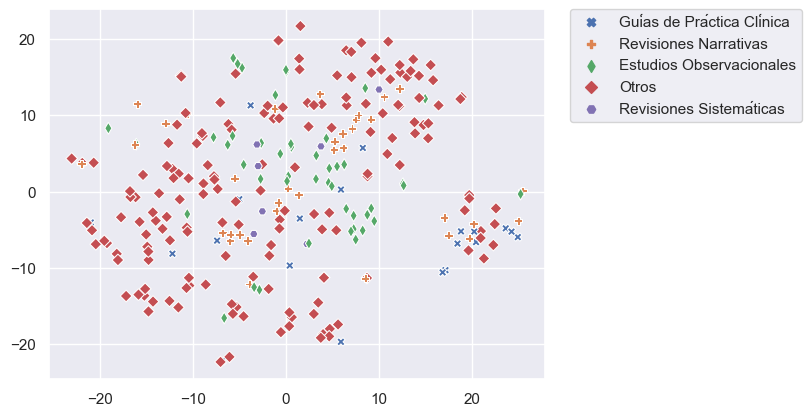
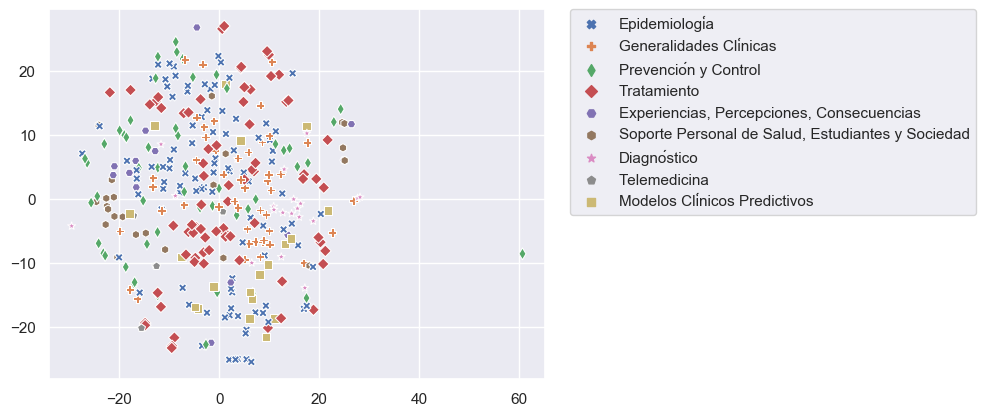
Our goal is to incorporate thousands of articles from the Elsevier and LitCovid collections to our COVID-19 repository. Because manual classification of these article is demanding and time-consuming, we have worked in an assisted classification strategy using supervised learning techniques and using manually classified articles as training data. We faced four problems to achieve this goal: tiny training data and imbalanced classes (categories with few examples) (Figure 1), categories with overlapping data (especially for topic) (Figure 2), and high dimensionality (few rows and a lot of columns).
 |
 |
|
 |
 |
|
 |
 |
|
 |
 |
|
Assisted classification
To address the challenge to classify the thousands of documents from Elsevier and LitCovid collections, we proposed an assisted curation strategy using the decision probability score assigned by the classifier to each document. For all automatically classified articles, we will show the probability score to the health professionals that participate in the project. Then, they can save time and effort by starting the manual review process using the top scores. After manually review and classification of a group of documents, we will able to establish a threshold of the probability score. All documents with probability score above this threshold will be able to be published automatically on our COVID-19 repository. In addition, the set of manually classified documents will be used to increase training data to better automatic classification.
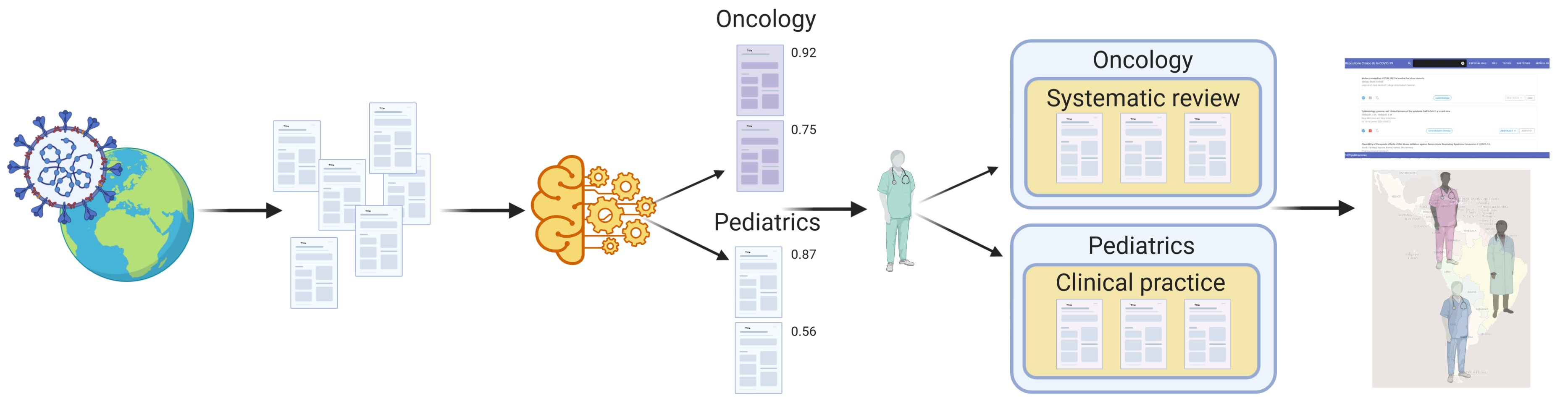 |
Methodology
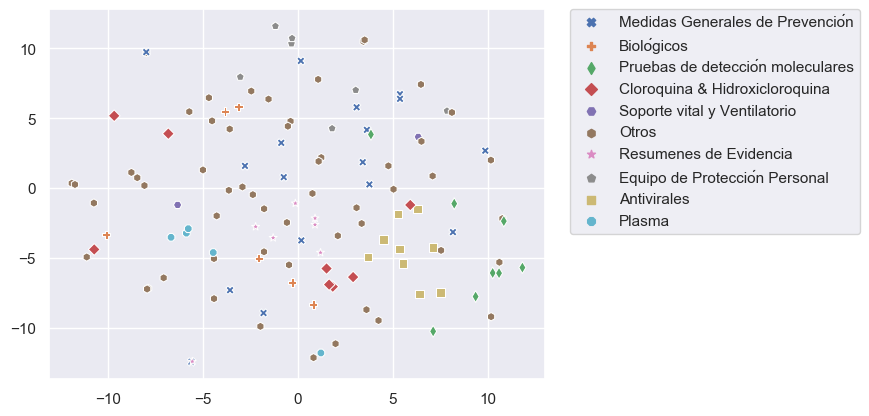
We deal with problems testing different techniques (Figure 3). For dimensionality reduction, we tested x2 (CHI2) and truncated singular value decomposition (truncated-SVD). Final tested dimensions were 50, 100, 150, 200, 250, and 300. To increase training data, we selected highly similar documents from Elsevier collection, using cosine similarity, to a category vector formed by all words of documents from the category. The last technique that we tested was feature creation using keywords manually selected from the most frequent words from all documents from a category.
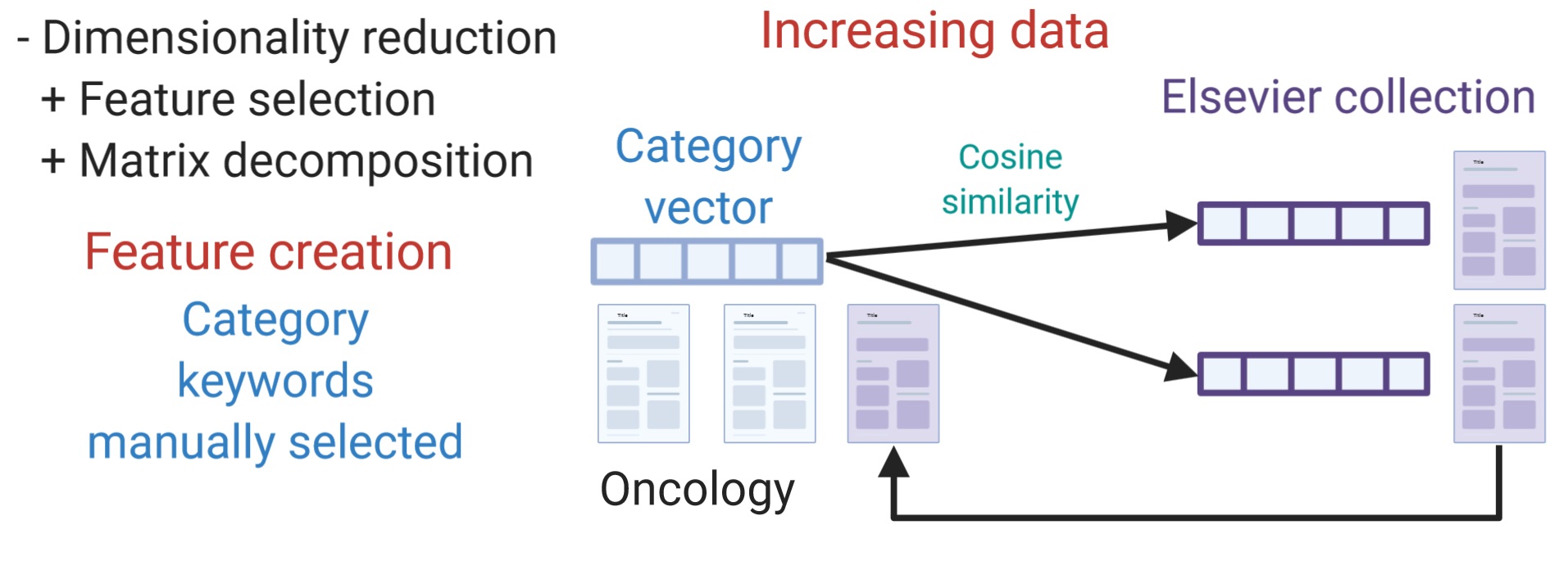 |
We tested different learning algorithms for automatic classification: Bernoulli Naïve Bayes (BernoulliNB), Multinomial Naïve Bayes (MultinomialNB), Complement Naïve Bayes (ComplementNB), Support Vector Machines (SVM) with Radial-basis function kernel (rbf) and linear kernel, k-nearest neighbors (kNN), Random Forest, and Stochastic Gradient Descent (SGDClassifier). Also, we tested binary and count vectorization of documents, as well as TF-IDF weighting. Hyperparameter tuning was performed.
Results
On the one hand, automatic classification worked better for branch and type classes (Table 1), both using lemmas from title, medium, keywords and abstract. Our strategy for increasing data using highly similar documents (Increase) enhanced scores. On the other hand, there is room to improve our results for classes topic and subtopic, where no increasing training data using lemmas from only title, medium and keywords was the best strategy. Dimensionality reduction increased scores of classifiers, three of them using truncated SVD and one using x2. A final observation is that while different learning algorithms achieved better for different classes, all classifiers performed better with TF-IDF vectorization.
Table 1. Scores of best classifiers and characteristics
| Class | Technique | Classifier | Features | Precision | Recall | F-score |
|---|---|---|---|---|---|---|
| Branch | Increase / Create | SGDClassifier, TF-IDF, SVD-200 | Title, medium, keywords and abstract | 0.77 | 0.68 | 0.70 |
| Type | Increase / Create | SVM-rbf, TF-IDF, SVD-50 | Title, medium, keywords and abstract | 0.81 | 0.80 | 0.80 |
| Topic | No increase / Create | SVM-rbf, TF-IDF, SVD-150 | Title, medium and keywords | 0.64 | 0.61 | 0.61 |
| Subtopic | No increase / Create | BernoulliNB, TF-IDF, CHI2-250 | Title, medium and keywords | 0.73 | 0.65 | 0.65 |